
PENINGKATAN KINERJA NAMED ENTITY RECOGNITION BAHASA INDONESIA MELALUI AUGMENTASI DATA BERBASIS LARGE LANGUAGE MODELS
DOI:
https://doi.org/10.51401/jinteks.v7i3.6403Keywords:
Augmentasi Data, Bahasa Indonesia, LLM, Named Entity Recognition, NERAbstract
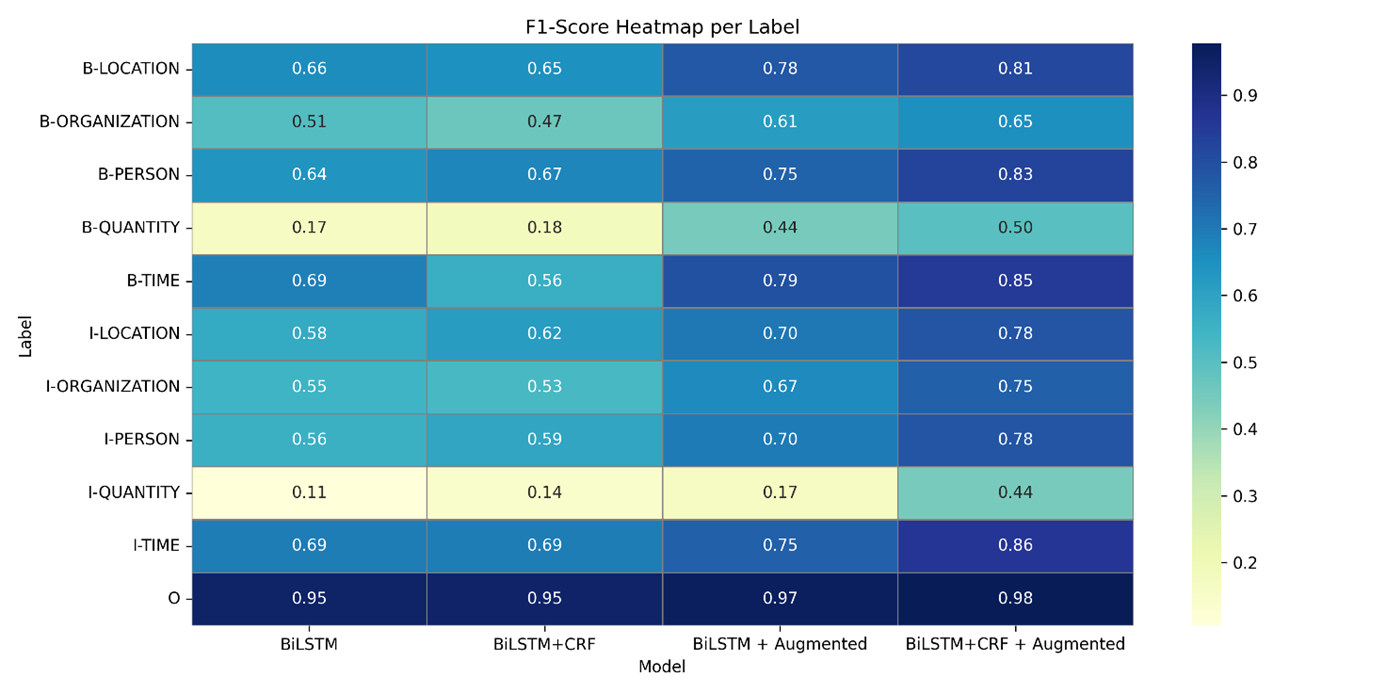
Named Entity Recognition (NER) merupakan salah satu tugas utama dalam Natural Language Processing (NLP) yang memerlukan ketersediaan data beranotasi dalam jumlah cukup. Bahasa Indonesia tergolong dalam kategori bahasa dengan sumber daya terbatas, sehingga performa model NER pada bahasa ini masih jauh dari optimal. Penelitian ini bertujuan meningkatkan kinerja NER Bahasa Indonesia melalui augmentasi data berbasis Large Language Models (LLM), khususnya GPT-4, dengan dua strategi: parafrasa kalimat dan substitusi entitas. Dataset yang digunakan berupa korpus berita berbahasa Indonesia dengan fokus pada entitas PERSON, ORGANIZATION, dan LOCATION. Model BiLSTM dan BiLSTM-CRF dilatih menggunakan data asli dan data hasil augmentasi. Hasil menunjukkan bahwa strategi augmentasi mampu meningkatkan performa model. Model BiLSTM-CRF dengan data augmentasi mencapai skor Macro F1 sebesar 0,75 dan Micro F1 sebesar 0,95, meningkat sekitar 20 poin dibandingkan dengan baseline tanpa augmentasi. Peningkatan terbesar tercatat pada entitas dengan frekuensi rendah seperti QUANTITY dan TIME. Temuan ini menunjukkan bahwa augmentasi berbasis LLM dapat digunakan dalam menghasilkan data sintetik yang memperkaya representasi model.
References
W. Gunawan, D. Suhartono, F. Purnomo, and A. Ongko, “Named-Entity Recognition for Indonesian Language using Bidirectional LSTM-CNNs,” Procedia Computer Science, vol. 135, pp. 425–432, 2018, doi: 10.1016/j.procs.2018.08.193.
H. T. Sukmana, J. Muslimin, A. F. Firmansyah, and L. K. Oh, “Building the Knowledge Graph for Zakat (KGZ) in Indonesian Language,” ASMScJ, vol. 16, pp. 1–10, Jul. 2021, doi: 10.32802/asmscj.2021.758.
S. O. Khairunnisa, Z. Chen, M. Komachi, and Editorial Office, “Improving Domain-Specific NER in the Indonesian Language Through Domain Transfer and Data Augmentation,” JACIII, vol. 28, no. 6, pp. 1299–1312, Nov. 2024, doi: 10.20965/jaciii.2024.p1299.
I. Budi, S. Bressan, G. Wahyudi, Z. A. Hasibuan, and B. A. A. Nazief, “Named Entity Recognition for the Indonesian Language: Combining Contextual, Morphological and Part-of-Speech Features into a Knowledge Engineering Approach,” in Discovery Science, vol. 3735, A. Hoffmann, H. Motoda, and T. Scheffer, Eds., in Lecture Notes in Computer Science, vol. 3735. , Berlin, Heidelberg: Springer Berlin Heidelberg, 2005, pp. 57–69. doi: 10.1007/11563983_7.
H. Khalid, G. Murtaza, and Q. Abbas, “Using Data Augmentation and Bidirectional Encoder Representations from Transformers for Improving Punjabi Named Entity Recognition,” ACM Trans. Asian Low-Resour. Lang. Inf. Process., vol. 22, no. 6, pp. 1–13, Jun. 2023, doi: 10.1145/3595861.
B. S. Lancheros, G. Corpas Pastor, and R. Mitkov, “Data augmentation and transfer learning for cross-lingual Named Entity Recognition in the biomedical domain,” Lang Resources & Evaluation, vol. 59, no. 2, pp. 665–684, Jun. 2025, doi: 10.1007/s10579-024-09738-8.
J. Ye et al., “LLM-DA: Data Augmentation via Large Language Models for Few-Shot Named Entity Recognition,” 2024, arXiv. doi: 10.48550/ARXIV.2402.14568.
A. S. Wibawa and A. Purwarianti, “Indonesian Named-entity Recognition for 15 Classes Using Ensemble Supervised Learning,” Procedia Computer Science, vol. 81, pp. 221–228, 2016, doi: 10.1016/j.procs.2016.04.053.
G. Lample, M. Ballesteros, S. Subramanian, K. Kawakami, and C. Dyer, “Neural Architectures for Named Entity Recognition,” in Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, California: Association for Computational Linguistics, 2016, pp. 260–270. doi: 10.18653/v1/N16-1030.
K. Zhang, D. Yue, and L. Zhuang, “Improving Chinese Clinical Named Entity Recognition Based on BiLSTM-CRF by Cross-Domain Transfer,” in Proceedings of the 2020 4th High Performance Computing and Cluster Technologies Conference & 2020 3rd International Conference on Big Data and Artificial Intelligence, in HPCCT & BDAI ’20. New York, NY, USA: Association for Computing Machinery, 2020, pp. 251–256. doi: 10.1145/3409501.3409527.
G. F. Shidik et al., “Indonesian disaster named entity recognition from multi source information using bidirectional LSTM (BiLSTM),” Journal of Open Innovation: Technology, Market, and Complexity, vol. 10, no. 3, p. 100358, Sep. 2024, doi: 10.1016/j.joitmc.2024.100358.
B. Wilie et al., “IndoNLU: Benchmark and Resources for Evaluating Indonesian Natural Language Understanding,” in Proceedings of the 1st Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 10th International Joint Conference on Natural Language Processing, Suzhou, China: Association for Computational Linguistics, 2020, pp. 843–857. doi: 10.18653/v1/2020.aacl-main.85.
S. O. Khairunnisa, A. Imankulova, and M. Komachi, “Towards a Standardized Dataset on Indonesian Named Entity Recognition,” in Proceedings of the 1st Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 10th International Joint Conference on Natural Language Processing: Student Research Workshop, Suzhou, China: Association for Computational Linguistics, 2020, pp. 64–71. doi: 10.18653/v1/2020.aacl-srw.10.
X. Dai and H. Adel, “An Analysis of Simple Data Augmentation for Named Entity Recognition,” in Proceedings of the 28th International Conference on Computational Linguistics, Barcelona, Spain (Online): International Committee on Computational Linguistics, 2020, pp. 3861–3867. doi: 10.18653/v1/2020.coling-main.343.
U. Yaseen and S. Langer, “Data Augmentation for Low-Resource Named Entity Recognition Using Backtranslation”.
W. Liu and X. Cui, “Improving Named Entity Recognition for Social Media with Data Augmentation,” Applied Sciences, vol. 13, no. 9, p. 5360, Apr. 2023, doi: 10.3390/app13095360.
A. Dao, H. Teranishi, Y. Matsumoto, F. Boudin, and A. Aizawa, “Overcoming Data Scarcity in Named Entity Recognition: Synthetic Data Generation with Large Language Models,” in Proceedings of the 24th Workshop on Biomedical Language Processing, D. Demner-Fushman, S. Ananiadou, M. Miwa, and J. Tsujii, Eds., Viena, Austria: Association for Computational Linguistics, Aug. 2025, pp. 328–340. [Online]. Available: https://aclanthology.org/2025.bionlp-1.28/
M. E. Rosadi and P. N. Andono, “A Comprehensive Evaluation of Machine Learning Classifiers in Named Entity Recognition,” 2024. doi: 10.1109/iSemantic63362.2024.10762517.
N. Manchev, “Building a named entity recognition model using a BiLSTM-CRF network.” Accessed: Jul. 29, 2025. [Online]. Available: https://domino.ai/blog/named-entity-recognition-ner-challenges-and-model
L. Yao, H. Huang, K.-W. Wang, S.-H. Chen, and Q. Xiong, “Fine-Grained Mechanical Chinese Named Entity Recognition Based on ALBERT-AttBiLSTM-CRF and Transfer Learning,” Symmetry, vol. 12, no. 12, p. 1986, Nov. 2020, doi: 10.3390/sym12121986.
Y. Syaifudin and A. Nurwidyantoro, “Quotations identification from Indonesian online news using rule-based method,” in 2016 International Seminar on Intelligent Technology and Its Applications (ISITIA), Lombok, Indonesia: IEEE, Jul. 2016, pp. 187–194. doi: 10.1109/ISITIA.2016.7828656.
Y. Ardhito, “Step-by-step NER Model for Bahasa Indonesia with PyTorch and Torchtext.” Accessed: Jun. 30, 2025. [Online]. Available: https://yoseflaw.medium.com/step-by-step-ner-model-for-bahasa-indonesia-with-pytorch-and-torchtext-6f94fca08406
X. Wang, X. Xu, D. Huang, and T. Zhang, “Multi-task Label-wise Transformer for Chinese Named Entity Recognition,” ACM Trans. Asian Low-Resour. Lang. Inf. Process., vol. 22, no. 4, Mar. 2023, doi: 10.1145/3576025.
Published
How to Cite
Issue
Section
Copyright (c) 2025 Dian Agustini, Muhammad Iqbal Firdaus, Muthia Farida, Muhammad Edya Rosadi, Hayati Noor, Riadhul Muttaqin

This work is licensed under a Creative Commons Attribution 4.0 International License.












